
If you are looking for an IDP solution, you are looking at extracting meaningful information from a large volume of documents. Most of these documents have tables, which is a structured presentation of information in rows and columns with underlying relationships among its elements and attributes.
Tables contain valuable information because tabular data allow for quick analyses as they are presented in a clean, structured, and concise format. Companies dealing with a large volume of documents may have to extract information from a large number of tables, perhaps millions, in structured or unstructured formats varying in structural semantics. This makes it more important than ever to choose an IDP solution that has a table extraction feature. However, you may need a solution that is not only high-value and effective but does more than extract information.
Challenges
Extracting information from tables has a unique set of challenges in IDP because of the heterogeneous nature of tables. Some of the key challenges in extracting tabular information are as follows:
- Detecting the table region accurately
- Detecting tables with multiple structures, layouts, and mostly different variations
- Detecting the exact boundaries
- Detecting the rows and columns and extracting information from them
- Segmentation based on semantics
- Identifying merged cells
- Denoising blank cells and irrelevant content
- Decoding the structural relationship of the table data

Infrrd’s Solution
Infrrd’s IDP solution already has a state-of-the-art, data-driven table extraction feature that uses AI-based technologies, such as deep learning, neural networks, and computer vision, to build machine learning algorithms for table detection and extraction. Not only is this process accurate and effective but also cognitive in nature, in handling multiple, diverse variations - an end-to-end trained model to address real-world scenarios. Moreover, the cognitive capabilities of Infrrd’s solution ensure that the trained data set for each extraction transforms to an exponential increase in accuracy and quality for future extractions.
A key benefit of Infrrd’s table extraction feature is that you can extract similar columns from multiple document types or variations. For example, assume you have received different documents from different vendors. You want to retrieve the item name, description, and total amount from these documents, whether it’s a utility bill, an invoice document, or a McDonald’s receipt. The trained Infrrd model can retrieve the same columns from all these documents using the table extraction feature. The advantage here is that our table extraction feature is applied globally to all document types. If the document you upload has a table, then it will be detected whether it’s an invoice, a receipt, an insurance form, or a loan document.
When you upload a document to Infrrd’s IDP platform, the system first checks whether the document contains tables. It then identifies the boundaries of each table and also the location and coordinates of each row and column. Next, it identifies and maps the headers for relevant columns. Finally, the tables are automatically extracted and relevant fields are mapped.
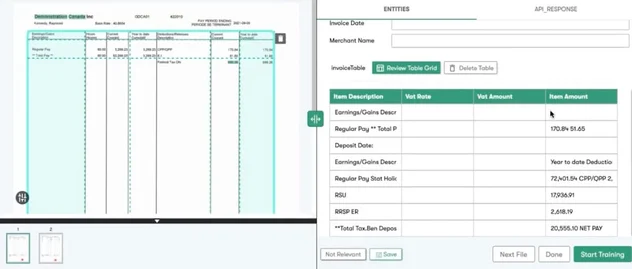
Fields are automatically recognized by the machine learning algorithms based on your requirements. You can play around with this table to correct any deviations from your prerequisites. Some of the powerful table-extraction capabilities of our solution are:
- Insert: Few rows or columns can be added to a table. For example, if the IDP system automatically extracted the item name and vat rate but you also need the quantity, you have an option to select and tag this column to the table.
- Redesign: The table border can be recaptured to include only the fields you need.
- Reorder: The position of the columns can be reordered by just selecting the table and dragging the respective column.
- Delete row/column: Specific columns and rows can be deleted if they don’t have data or you don’t need them.
- Delete table: If the table detection was incorrect or you want another table you can delete the current table and redraw the boundaries.
- Borderless: Our algorithms will detect tables whether they have borders or not.
- Combine: If the table is extended to multiple pages of the document it is combined and extracted into a single table.
Infrrd’s table extraction feature enhances the capabilities and user experience for your IDP solution.
Schedule a table extraction demo







