
“Don’t trust everything you see; even salt looks like sugar.” This saying is a reminder that appearances can be deceiving. In today’s world of overwhelming information, distinguishing fact from fluff becomes even more challenging. In the realm of AI, the same principle applies. Just because an AI model provides an answer doesn’t mean it’s always the right one.
In fact, even the most advanced AI systems—like Large Language Models (LLMs)—can struggle with accuracy. These models can process vast amounts of text, analyze complex data, and generate responses almost instantly. But how do you know if what they’re telling you is correct? This is where confidence scores come into play. Confidence scores are like the AI's version of a gut feeling. They tell us how certain the model is about its answer. Think of them as a safety net that helps businesses and users like you navigate the sea of data LLMs provide.
Without confidence scores, you'd be left guessing whether an extracted phone number or key piece of data is valid. With them, you can make more informed decisions about what to trust. So, what exactly are confidence scores? How can they be used to improve LLM accuracy, and why do they matter for businesses and data-driven decisions?
In this blog, we’ll break down the role of LLMs, dive into how confidence scores enhance their trustworthiness, explore real-world examples, and discuss best practices to make the most of these powerful AI tools. Ready?
What are Large Language Models (LLMs)?
At their core, Large Language Models (LLMs) are advanced AI systems designed to understand, interpret, and generate human language. Powered by neural networks, they process vast amounts of text data to "learn" language patterns, structure, and context. Think of them as incredibly smart assistants that help with everything from text summarization to answering questions or extracting specific information from a sea of documents.
These models, like OpenAI's GPT-3 and GPT-4, are trained on enormous datasets, which allow them to generate text and provide insights that can mimic human conversation. However, as smart as these models are, they aren't without their challenges. The most significant one is accuracy—especially while handling large datasets or specialized tasks for extraction.

Does the L in LLMs Actually Stand for Limitations?
LLMs process language through something called tokens. A token can be a word or part of a word, depending on the complexity of the language model. For instance, "unhappiness" might be split into "un" and "happiness." These tokens are the building blocks that the model uses to understand and generate text. But here's the catch: every LLM has a token limit.
Early models, like GPT-3.5, were limited to around 4,096 tokens, meaning they could only process a limited amount of text at a time. This often led to situations where the model would lose track of context in long documents. This is where you put your confidence in confidence scores.
What are Confidence Scores in LLMs?
Confidence scores are a measure of certainty about the predictions or outputs generated by the model. Think of them as a thermometer that tells you how likely the model is to be correct about its answer. The higher the confidence score, the more reliable the output is.
Imagine you're using an LLM to extract a phone number from a document. The model might come across a string of digits and output something like "Phone number: 123-456-7890." Now, how confident is it that this is indeed a phone number? The confidence score associated with that output might tell you it's 95% confident. This helps the user know when they should trust the output and when they should ask for further verification or corrections.
How LLMs Get it Right (or Wrong) with Phone Numbers

Let’s say you're processing a ten-page document, and you want to know the applicant’s phone number. However, because of token limits in GPT-3 (up to 4k tokens), the model might only see the first page, which doesn’t contain the applicant’s number but does contain another phone number. In this case, when asked, “What is the applicant's phone number?” the LLM might return the phone number it sees on the first page, which is incorrect.
Here’s where the genius of confidence scores comes in. The model is designed to respond even when it is uncertain. But what if the model could assess how confident it is in the response it gives?
Instead of returning an answer blindly, we modified the LLM's prompt: “If you are not confident in the phone number, do not provide any answer. Instead, return ‘N/A’ or ‘Not found.’”
Now, the model only returns a valid phone number if it’s confident that the data it processed is correct. If the model isn’t confident (because the correct phone number is on a different page), it returns “N/A,” allowing the system to filter out incorrect answers and only display valid results.
This technique minimizes the risk of incorrect data and maximizes the model’s reliability.
Does Confidence Score "Cherry-Pick" the Best Information?
Confidence scores are numerical values that tell you how sure an LLM is about the answer it provides. Say for instance, in an AI model like Infrrd, when extracting data such as names, phone numbers, or financial figures from a document, each extracted value is assigned a confidence score. If the score is high (say 90%), it means the model is quite sure that the extracted information is accurate. If the score is low (say 50%), it means the model is less certain, and that information may require further validation.
When processing multiple pages or chunks of data, an LLM might generate a lower confidence score for if it’s unsure about a certain piece of information. If an answer from one page seems to conflict with another page, these scores help the system identify which page is likely to be more accurate. This allows the system to "cherry-pick" the most reliable information and eliminate irrelevant or incorrect data.
The Evolution of Token Limitations: From Splitting to Merging Pages
In the early days of LLMs, token limitations posed significant challenges. For example, GPT-3 had a token limit of 4k tokens, meaning that longer documents had to be split into multiple chunks, each of which would be processed separately. This created a challenge where the model couldn't maintain context across chunks. If one chunk contained a part of a phone number, and another chunk contained a different part, the LLM would struggle to understand that these fragments were related.
With the release of GPT-4 and its increased token limit of up to 100k tokens, this issue became much less problematic. Now, instead of splitting documents, the model could process entire documents, maintaining context across all pages, and improving the accuracy of the extracted data.
Putting the Confident Score in LLMs
LLMs, especially when coupled with confidence scores, are transforming the way businesses handle data. The power of these models lies in their ability to rapidly process and extract valuable insights from complex documents, which would otherwise take hours or even days for humans to manage. With LLMs, tasks such as extracting names, phone numbers, or financial figures become a matter of seconds, with the added benefit of reducing human error.
While these AI-driven models are incredibly advanced, the confidence they display in their answers makes all the difference. The confidence score is essentially the model’s way of telling you how certain it is about the information it’s providing. Trusting only high-confidence responses ensures that you can rely on your data with more certainty, mitigating the risk of making decisions based on inaccurate or incomplete information.
In real-world applications, this means fewer costly mistakes and less wasted time on double-checking data. When you empower your business with LLMs that know when to "cherry-pick" the most reliable information, you gain a significant edge. You don't just have a tool that assists you—LLMs become a critical asset in enhancing operational efficiency, driving better decisions, and ultimately helping you stay ahead in a competitive marketplace.
The ability to automate data extraction, while ensuring high accuracy with the use of confidence scores, is a game-changer for industries like finance, healthcare, and customer service. By fully embracing the potential of confidence score in LLM, companies are paving the way for smarter, faster, and more reliable decision-making processes, all powered by the intelligence of AI.

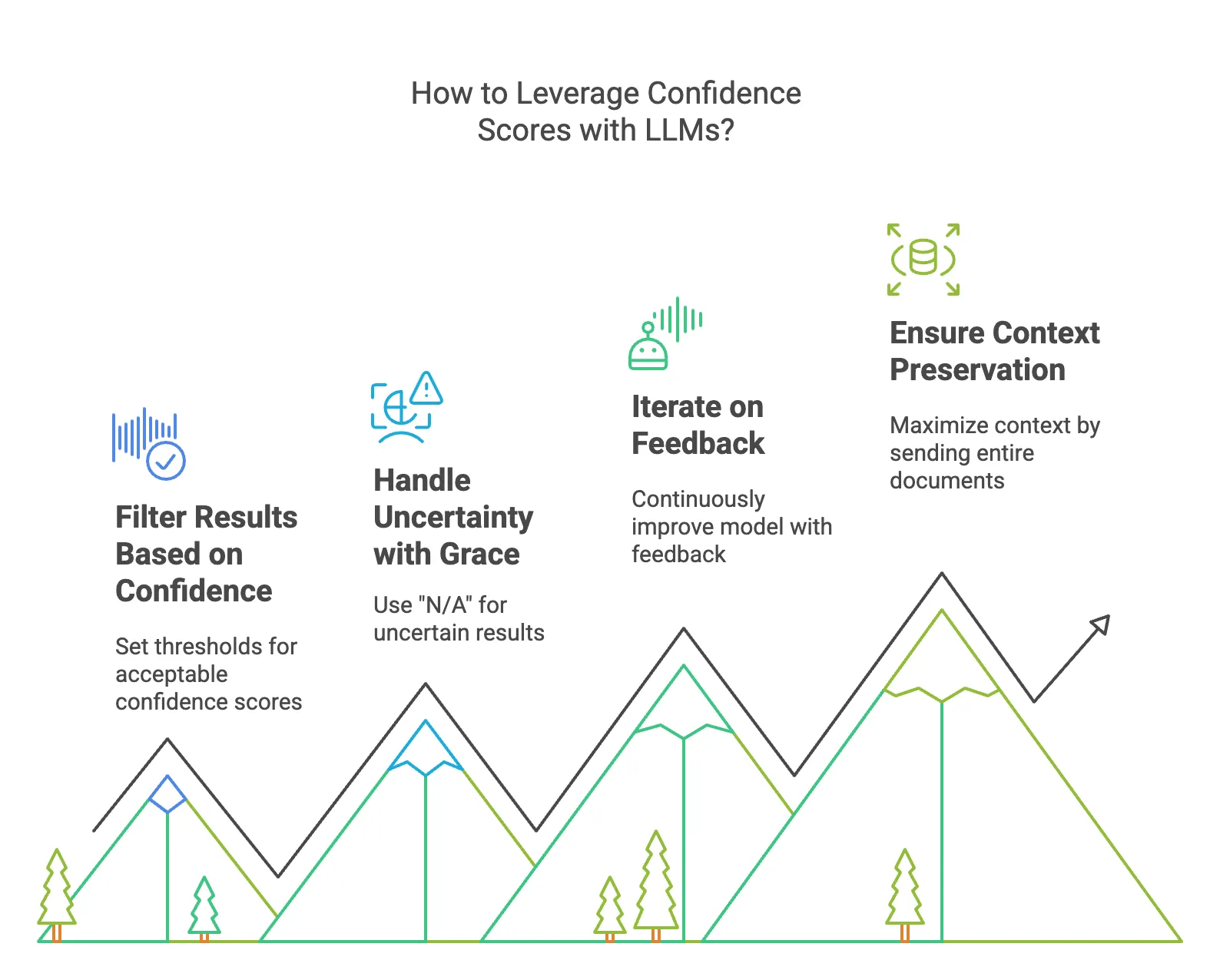
Best Practices for Leveraging Confidence Scores with LLMs
- Filter Results Based on Confidence: Always set thresholds for acceptable confidence scores. For example, only accept results with confidence scores above 80%. Anything lower should be flagged for review.
- Handle Uncertainty with Grace: Use the “N/A” or “Not found” approach when the model isn't confident in a result. This ensures that you don’t end up with incorrect data that could cause downstream problems.
- Iterate on Feedback: Continuously feedback on the model's performance, especially when confidence scores fall below expectations. Over time, this iterative process helps improve the model’s reliability.
- Ensure Context Preservation: With the improved token limits in models like GPT-4, ensure you are maximizing the model’s potential by sending entire documents for analysis, allowing the LLM to retain all the context.
All in all, trusting high-confidence results isn’t just a matter of convenience—it’s a strategic move that enhances operational excellence, minimizes risks, and ensures data integrity. As businesses increasingly rely on LLMs for automation and decision-making, understanding and leveraging confidence scores becomes crucial. These scores don’t just measure accuracy; they provide a transparent view into the reliability of AI-generated outputs, enabling businesses to make smarter, data-driven decisions with confidence.
The best method for business operations is here, and with LLMs guided by confidence scores, organizations can embrace AI-powered efficiency without compromising accuracy. Want to see how confidence scores can enhance your data accuracy and transform your decision-making process?
Want to see how confidence scores can improve your data accuracy and decision-making? Talk to an expert today to explore how AI-powered insights can transform your business.

Bhavika Bhatia is a Product Copywriter at Infrrd who blends curiosity with clarity to craft content that makes complex tech feel simple and human. With a background in philosophy and a knack for storytelling, she turns big ideas into meaningful narratives. Outside of work, you’ll find her chasing the perfect café corner, binge-watching a new series, or lost in a book that sparks more questions than answers





